State Example
This tutorial is for using states. We will use states in this example to write a simple dataflow that counts the number of entries sent to a topic. The following page contains an indepth explanation about states.
Prerequisites
This guide uses local Fluvio cluster. If you need to install it, please follow the instructions at here.
Dataflow
Overview
We will define a service that contains a state which counts how much entries have entered the source.
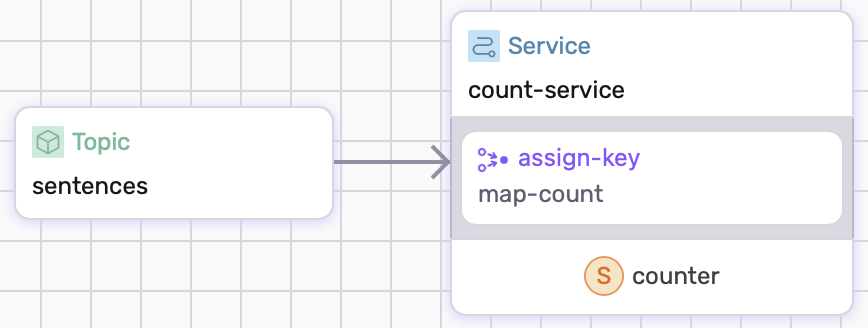
Service With State
In this section we will show how to write a dataflow with a primitive state. The service needs to include a state and a partition. Inside the state, we will define a key-value pair. For our case, we are only using a primitive key-value pair(String -> u32). Inside the partition, we will define an assign-key and update-state. The function in assign-key will take the input from the source and map it to a key. The function in update-state will define the logic how the state is updated.
count-service:
sources:
- type: topic
id: sentences
states:
(...)
partition:
assign-key:
(...)
update-state:
(...)
1. State definition
For our example, we defined a simple key-value pair.
states:
counter:
type: keyed-state
properties:
key:
type: string
value:
type: u32
2. Assign key
In our state, we have to map inputs to a key in our state. But for our example, our mapping function is trivial. All inputs are mapped to the same output. In most other cases, you can modify the mapping to take on more complicated logic.
assign-key:
run: |
fn map_count(input: String) -> Result<String> {
Ok("counter".to_string())
}
3. Updating State
The following part of the dataflow defines how the value of the mapped function is updated. In our case, all we want to do is increment the counter by 1. Because the way we assigned our key, all inputs will increment the same key.
run: |
fn add_count(input: String) -> Result<()> {
counter().increment(1);
Ok(())
}
Running the Example
Copy and paste following config and save it as dataflow.yaml.
# dataflow.yaml
apiVersion: 0.5.0
meta:
name: state-example
version: 0.1.0
namespace: examples
config:
converter: raw
topics:
sentences:
schema:
value:
type: string
services:
count-service:
sources:
- type: topic
id: sentences
states:
counter:
type: keyed-state
properties:
key:
type: string
value:
type: u32
partition:
assign-key:
run: |
fn map_count(input: String) -> Result<String> {
Ok("counter".to_string())
}
update-state:
run: |
fn add_count(input: String) -> Result<()> {
counter().increment(1);
Ok(())
}
To run example:
$ sdf run
Produce data
You can produce data to the sentence topic via
$ echo 'hello' | fluvio produce sentences
$ echo 'hello' | fluvio produce sentences
$ echo 'hello' | fluvio produce sentences
It does not matter the input as the dataflow only counts entries.
Consume data
You can see how much entries have entered sentences through using sdf's CI
>> show state count-service/counter/state
Key Window Value
counter * 3
Cleanup
Exit sdf terminal and clean-up. The --force flag removes the topics:
$ sdf clean --force
Conclusion
We just implement another example with states.